Einführung in das IPFS (InterPlanetary File System)
Was ist IPFS bzw. wie funktioniert IPFS?
IPFS ist ein Protokoll und ein Netzwerk um ein verteiltes Dateisystem zu bilden, welches auf P2P (peer-to-peer) Methoden beruht und einige der Schwachpunkte des derzeitigen Internets eliminieren möchte. Dabei verwendet es einige schon vorhandene Technologien wie z.B. Git, Blockchain oder BitTorrent und vereint diese zu einem Gesamtkonzept, welches es ermöglicht, Dateien dezentral im Internet zu speichern und wiederzufinden. Dateien können hierbei, im Gegensatz zu Torrents welche einen speziellen Client benötigen, direkt im Browser abgerufen werden.
Was ist die Motivation hinter IPFS bzw. die Schwachpunkte des heutigen Internets?
In erster Linie die Abhängigkeit von einigen wenigen zentralen Cloud-Anbietern. So ist heute ein großer Teil der Webseiten z.B. bei Amazon gehostet bzw. verwendet deren Cloud-Speicher. So gut Amazon seine Datacenter auch ausgebaut und weltweit platziert hat, es besteht dennoch eine große Abhängigkeit von einem einzelnen Dienstleister. Die Vergangenheit hat gezeigt, dass es auch hier immer wieder zu Problemen kommen kann und Daten verloren gehen. Ganz abgesehen von Fragen, inwieweit wir einer einzigen Firma soweit vertrauen sollen, eine derartige Menge an Daten zu verwalten und in der Hand zu haben.
IPFS bietet eine Möglichkeit, die Speicherung von Daten dezentral zu gestalten. D.h. jeder kann sozusagen ein kleiner Teil eines Cloud-Netzwerkes werden und einen Node betreiben. Stellt man eine Datei ins IPFS, wird sie automatisch auf verschiedene Knoten verteilt. Die Datei wird hier über einen eindeutigen kryptographischen Hash angesprochen. Fordert ein Client diese Datei an (z.B. eine Webseite), so kann diese vom am nächsten gelegenen Knoten geliefert werden und dies kann somit oft schneller erfolgen als wenn sie von einem Datacenter geliefert werden müsste.
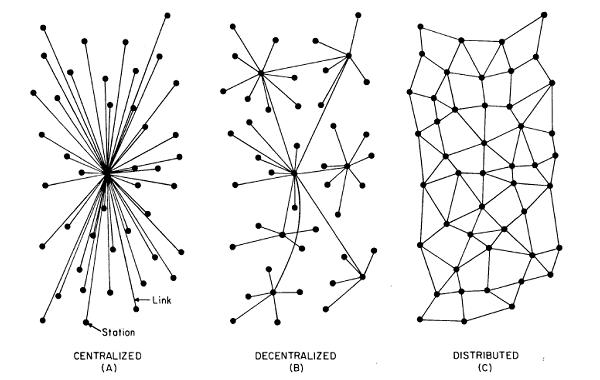
Um diese Unabhängigkeit vom tatsächlichen Speicherort einer Datei zu erreichen, gibt es einen entscheidenden Unterschied zum Http-Protokoll: Die Adressierung erfolgt über Inhalte und nicht über Speicherorte. Was heißt das?
Momentan wird eine Website indirekt über den Speicherort angesproche: z.B. http://www.mysite.com/index.html liefert über DNS eine IP-Adresse hinter der ein Server läuft welche die angeforderte Datei index.html bereithält. Fällt dieser Server aus, ist auch die Datei nicht abrufbar.
Unter IPFS wird der Inhalt adressiert, d.h. die URL enthält den eindeutigen Hash der Datei und überlässt es dem IPFS Netzwerk, die besten Nodes für die Auslieferung zu finden. Eine Datei liegt hierfür nicht als Gesamtes auf einem Node, sondern ist in viele kleine Teile aufgesplittet welche auf verschiedene Nodes aufgeteilt sind und diese Teile werden dann wieder zu einem Gesamten zusammengefügt. Durch die gleichzeitige Übertragung der Datei-„Teilchen“ von mehreren Nodes ergibt sich ein Geschwindigkeitsvorteil im Gegensatz zum Übertragen der gesamten Datei nur von einem Server. Ein Beispiel für eine solche URL: https://ipfs.io/ipfs/QmT3fT1CtH3hWqXdkQW6iqCWgRttfpN9u8RbzwKHAv9Wky
Da die Datei über den kryptographischen Hash angesprochen wird, kann auch garantiert werden, dass keiner der am Netzwerk beteiligten Akteure die Datei geändert hat. Da ich in einem verteilten Netzwerk die Teilnehmer nicht kenne ist dies eine wichtige Voraussetzung, um das Vertrauen herzustellen.
Ändert man die Datei und fügt sie wieder in das IPFS Netzwerk hinzu, ändert sich auch der Hash. Alte Versionen einer Datei werden somit behalten und können jederzeit wieder gelesen werden. Da es für manche Anwendungen aber unpraktisch wäre, eine Datei welche sich laufend ändert immer unter einem neuen Hash anzusprechen, wurde ein Namenssystem IPNS eingeführt, um eine Datei immer unter einem Hash ansprechen zu können, unabhängig von dessen Version.
Soweit mein aktueller Wissensstand zu IPFS, welchen ich hoffe in den nächsten Wochen noch weiter ausbauen zu können. Da IPFS noch in der Alpha-Version ist, kann sich noch einiges ändern, aber der Ansatz erscheint sehr vielversprechend. Schon jetzt gibt es eine Vielzahl von Projekten, welche auf IPFS aufbauen.
Zusammenfassung
- Jede Datei bekommt einen einzigartigen kryptographischen Hash-Wert, sozusagen der Fingerabdruck
- IPFS entfernt automatisch Duplikate, also doppelte Versionen des gleichen Inhalts
- IPFS speichert die Versionsgeschichte jeder Datei
- Jeder Netzwerk-Knoten speichert den Inhalt an dem er interessiert ist und Index-Informationen um herauszufinden, wer was gespeichert hat
- Beim Abrufen einer Datei fragt man das Netzwerk, welcher Knoten die Datei liefern kann
Links
- https://ipfs.io/
- https://filecoin.io/ Coin-System welches auf IPFS aufsetzt und den teilnehmenden Nodes eine Bezahlung über Cryptocoins generieren kann
- https://peerpad.net/ Dezentralisiertes Tool zur online Zusammenarbeit an einem Dokument
- https://d.tube/ Video-Plattform ähnlich Youtube, welches die Videos in IPFS gespeichert hat
- https://github.com/orbitdb/orbit-db P2P-Datenbank welche ihre Daten in IPFS speichert
test